Spark Executor는 Apache Spark에서 작업(Task)을 실제로 실행하는 프로세스로, 클러스터의 각 노드에서 실행됩니다.
Spark 애플리케이션이 실행될 때, Executor는 드라이버(Driver)로부터 명령을 받고 RDD(Resilient Distributed Dataset) 변환 및 액션을 수행합니다.
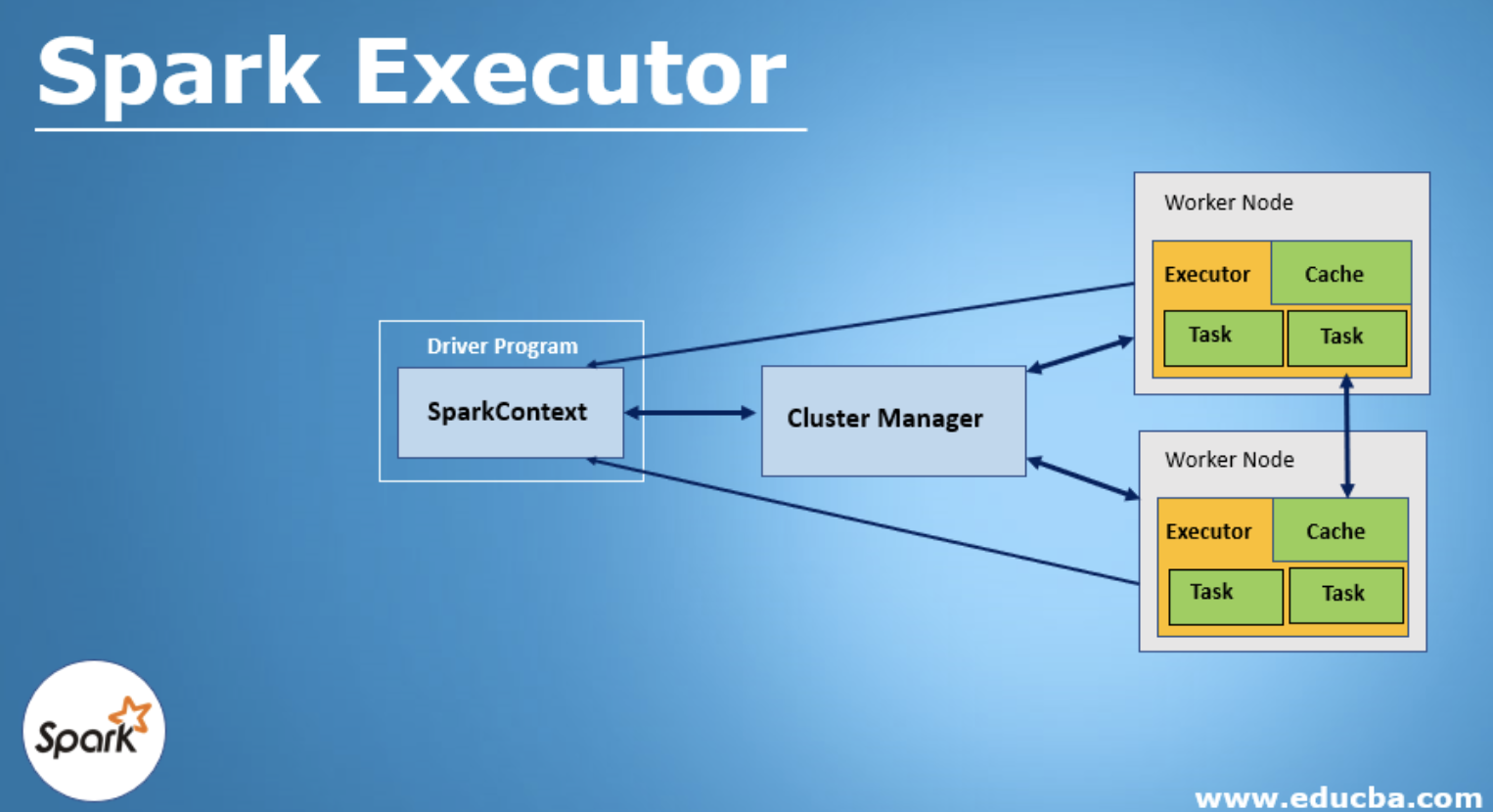
Executor의 역할
1. Task 실행
• Spark Driver가 분배한 Task(작업 단위)를 실행
• Task는 RDD 연산, 데이터 로드 및 변환을 수행
2. 메모리 관리
• Executor는 캐시된 RDD 및 데이터 처리를 위한 메모리를 관리
• Spark의 JVM Heap Memory를 활용하여 연산 수행
3. 데이터 저장 및 교환
• 데이터가 파티션 단위로 Executor에 저장되며, 필요 시 다른 Executor와 데이터 교환
4. 결과 반환
• 각 Task가 수행된 후 결과를 Spark Driver에 반환
Executor 실행 과정
1. Spark 애플리케이션 시작
2. Cluster Manager(YARN, Kubernetes, Mesos 등)가 Executor 할당
3. Driver가 Task를 Executor로 전송
4. Executor가 Task 실행 및 데이터 저장/교환
5. 작업 완료 후 결과 반환 또는 저장
Executor의 구성 요소
• Task Slot: Executor에서 병렬로 실행할 수 있는 작업 수
• JVM Heap Memory:
• Execution Memory: 연산 중 필요한 메모리 (Shuffle, Join, Aggregation 등)
• Storage Memory: 캐싱된 데이터 저장
• Shuffle Service: Executor 간 데이터 교환 시 사용
Executor 설정
• Spark에서는 Executor의 개수, 메모리 크기 등을 설정하여 최적화할 수 있습니다
| 설정 | 설명 | 예시 |
| --num-executors | Executor 개수 지정 | --num-executors 10 |
| --executor-cores | Executor 당 CPU 코어 수 | --executor-cores 4 |
| --executor-memory | Executor의 JVM 메모리 크기 | --executor-memory 8G |
Executor와 Driver의 차이
| 구분 | Driver Executor |
| 역할 | 작업을 분배하고 관리 작업(Task)을 실행 |
| 위치 | 클러스터의 Master 노드 또는 Client 클러스터의 Worker 노드 |
| 실행 시간 | 애플리케이션이 끝날 때까지 유지 작업이 끝나면 종료될 수 있음 |
Executor 장애 처리
• Executor가 비정상 종료되면 Spark는 새로운 Executor를 요청하여 작업을 다시 할당
• spark.task.maxFailures 값을 조정하여 재시도 횟수 설정 가능
'IT > Spark' 카테고리의 다른 글
| Apache Spark 2.4 → 3.0 마이그레이션: RDD 및 Dataset 기반 병렬 처리 개선점 (1) | 2025.03.18 |
|---|---|
| Apache Spark - Batch와 Streaming Processing 정의 및 비교 (1) | 2025.02.26 |
| PySpark을 Oozie에 등록하여 워크플로우를 실행하는 방법 (0) | 2025.02.23 |
| RDD(Resilient Distributed Dataset) (1) | 2025.02.14 |
| RDD(Resilient Distributed Dataset) (0) | 2025.02.08 |



